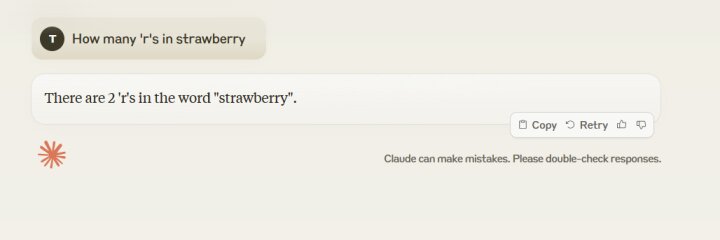
Case one: Naive prompt that results in a very common hallucination (it guesses and most LLMs currently tend to answer this question wrong)
Case two: Prompt which pushes the LLM to create the number of 'r's in the word into the current context as part of its response instead of relying on a 'guess'. This allows it to accurately produce the correct answer each time.